


Locating web elements is an important aspect of web application automation and a core activity in automation script development. In order to proceed with this identification of HTML elements, we might need certain definite attributes like id, class, name and so on. However, in certain cases, it might so happen that there might be no unique attributes associated with web elements. This might be the result of poor development practices or due to the presence of dynamic web elements. In such a case, the mechanism through which location of web elements is facilitated is through XPath in Selenium. It acts as a query language which helps extract entities from the Document Object Model (DOM).
In this blog on XPath in Selenium, we will try to look at some of the crucial aspects of XPath Selenium, in terms of what it is, types of XPath as well as the different XPath expressions which can be used for locating different kinds of elements.
What is XPath?
XML Path or XPath in Selenium is a technique to query XML documents and to navigate the HTML structure of a webpage. The language can be used to write XPath query/script which in turn can help in locating and identifying web elements on a webpage using XML Path Expression. XPath in Selenium can be used for HTML as well as XML documents.


The general locators in Selenium may at times, might not suffice to locate all DOM elements of a HTML document. This is where XPath Selenium steps in. By way of helping in providing for dynamic search of elements, it provides for much needed flexibility to adjust a locator as per one?s needs.
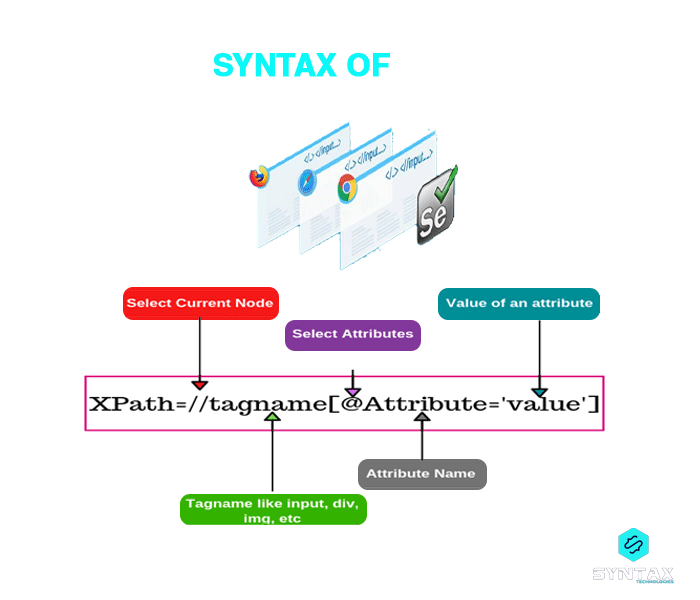
Syntax of XPath
XPath=//tagname[@Attribute=?Value?]
//: To select the current node
Tagname: Tag name of a specific node
@: To select the attribute
Attribute: It is the attribute name of the node
Value: It is the value of the node
Types of XPath Locators
ID: Helps in locating element with the help of the ID of the element
Name: Helps in locating element with the help of the Name of the element
Classname: Helps in locating element with the help of the Classname of the element
XPath: Helps in locating dynamic elements and traverse between different elements of the webpage
Link text: Helps in locating element with the help of the link of a text
CSS Path: Helps in locating elements which have no class, ID or name
Types of XPath
- Absolute XPath
This type is used for directly locating a particular element on the webpage. It is one of the direct ways of finding an element wherein the expression of the XPath is formed by using the selection from the root node. The XPath in this case begins with a single slash (?/?) and it passes over from the root to the whole Document Object Model (DOM) in order to locate the specific element.
A major shortcoming of this approach is that any change in the path of the element would result in a failed XPath expression.
For instance: /html/body/form/input [5]
This kind of search would begin with the first form tag in the page body and would then select the fifth input field in the form.
2. Relative XPath
In case of Relative XPath in Selenium, the expression starts from the middle of the HTML DOM structure. The expression is marked by beginning it with a double slash (//) which denotes the current node. The search begins from the mentioned tagname and the string value, and helps in searching elements anywhere on the webpage.
The major advantage of this approach is that it is easy to use, is more compact and is less prone to be broken as compared to Absolute XPath Selenium.
For instance: Relative XPath: //input[@name=?email?]
In the given expression of XPath in Selenium, we shall begin our search from the current node which has the tagname as input, whose attribute is name and value is email.
?
XPath Functions
As an Automation Testing tool, Selenium does offer useful features for the identification of elements and objects on a webpage. However, at times it so happens that elements on a webpage may have the same attributes due to which it becomes difficult to identify them. Similarity in names and attributes of elements, render it quite challenging for Selenium to identify any one particular element. In such situations, XPath Functions come to our rescue.
XPath Contains () Function
This function can be used to successfully create an XPath expression in situation when the value of any attribute changes dynamically. In such a scenario, the contain function helps in locating a particular web element with the help of the available partial text.
In order for the function to be successful, the attribute of the tag must validate to locate the specific web element and the value of the attribute must be a partial value which the attribute must contain.
For instance: //tagname[contains(@attribute,?value_of_attribute?)]
XPath Starts-with() Function
This function can be used to successfully create an XPath expression in situation when the value of an attribute changes on refresh or as a result of any other dynamic operation on the webpage. The starts-with function is then used to match the starting text of the attribute, in order to locate the element whose value might have had changed. Additionally, the function can also be used for locating elements whose attribute value remains static or where it starts with some specific character or a sequence of characters.
In order for the function to be successful, the attribute of the tag must validate to locate the specific web element and the value of the attribute must be a partial value of the attribute with which the attribute is expected to start.
For instance: //tagname[starts-with(@attribute,?Part_of_Attribute_Value?)]
XPath Text() Function
This particular XPath Selenium function can be used to locate elements on a webpage on the basis of the text of the element. The text function seeks to match the exact text element and thereby locate the element within the set of text nodes. Additionally, in order for this function to be effective, the element which is sought to be located should be present in string form.
The text() function can be used to provide us with the text of the element as it is identified with the tagname and is compared with the value of the attribute provided.
For instance: //tagname[text()=?Text of the element?]
XPath Axes Methods
The elements of XML DOM are arranged in a specific manner. They are present in a hierarchical structure and are generally located by way of either of the two types of XPath: Absolute XPath or Relative XPath. In order for this operation to be successful, XPath in Selenium provides certain attributes which are known as XPath Axis.
The XPath Axes Methods are used to identify relation with the current node and thereby help to locate the relative nodes. The XPath Axes Methods basically utilizes the relation between the different nodes in order to locate them within the DOM structure.
In this section, we will look at some of the common XPath Axes Methods.
Conclusion
By the end of this blog, I am sure you must have acquired a decent understanding of how XPath in Selenium works. It is evident that while the need to locate web elements might be an important concern during Automation Testing, especially cross-browser testing; the conventional methods might not always work due to some or the other reason. In such situations, XPath in Selenium provides the way out for locating web elements. However, it is important to be clear of the viability of the different types and functions of XPath Selenium in different situations, depending upon functional needs and the complexities of the DOM structure. This will help you to create scripts which are neat, effective and robust.
XPath Selenium is definitely a laudable feature of this quite popular Test Automation Tool. Moreover, Selenium is definitely regarded as one of the first Software Testing Tools of choice for Software Development Engineers in Test (SDETs). If you wish to cultivate the skills needed to be a SDET and grab this coveted position; enrol now for our SDET Automation Course.
